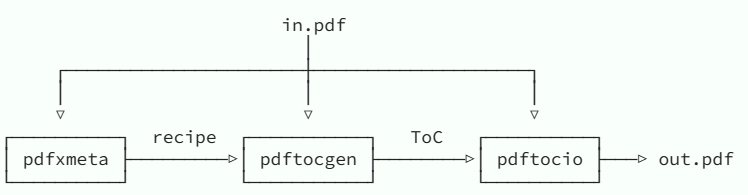
pdf.tocgen使用
工具链:
pdfxmeta(提取元数据)+pdftocgen(生成目标表)+pdftocio(添加目录)。
测试来源:为 PDF 增加目录 - 少数派 (sspai.com)
测试案例:
pdfxmeta提取元数据
1 2 3
pdfxmeta.exe -p 1 -a 1 .\30堂证券投资通识课_无目录版.pdf "证券投资基础" pdfxmeta -p 1 -a 2 30堂证券投资通识课_无目录版.pdf "⼀、了解并掌握证券投资这⻔艺术" pdfxmeta -p 1 -a 3 30堂证券投资通识课_无目录版.pdf "投资者适应性"
拷贝输出。如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55
[[heading]] # 第⼀讲 证券投资基础 level = 1 greedy = true font.name = "Unnamed-T3" font.size = 24.000001907348633 # font.size_tolerance = 1e-5 # font.color = 0x24292e # font.superscript = false # font.italic = false # font.serif = false # font.monospace = false # font.bold = false # bbox.left = 50.5 # bbox.top = 44.13671875 # bbox.right = 271.6211242675781 # bbox.bottom = 72.80078125 # bbox.tolerance = 1e-5 [[heading]] # ⼀、了解并掌握证券投资这⻔艺术🐰 level = 2 greedy = true font.name = "Unnamed-T3" font.size = 18.000001907348633 # font.size_tolerance = 1e-5 # font.color = 0x24292e # font.superscript = false # font.italic = false # font.serif = false # font.monospace = false # font.bold = false # bbox.left = 50.5 # bbox.top = 99.22750854492188 # bbox.right = 338.5000305175781 # bbox.bottom = 125.1911849975586 # bbox.tolerance = 1e-5 [[heading]] # 🍼 投资者适应性 level = 3 greedy = true font.name = "Unnamed-T3" font.size = 15.000000953674316 # font.size_tolerance = 1e-5 # font.color = 0x24292e # font.superscript = false # font.italic = false # font.serif = false # font.monospace = false # font.bold = false # bbox.left = 50.5 # bbox.top = 145.73126220703125 # bbox.right = 158.927734375 # bbox.bottom = 164.37550354003906 # bbox.tolerance = 1e-5
使用元数据,扫描PDF获取目录信息:
1 2 3 4 5 6
# windows编码问题,ps终端写法 $env:PYTHONUTF8=1 # CMD:Set PYTHONUTF8=1 # ps管道写法 get-Content .\recipe.toml | pdftocgen.exe .\30堂证券投资通识课_无目录版.pdf # CMD:pdftocgen 30堂证券投资通识课_无目录版.pdf < recipe.toml # 直接用管道输出文件编码为utf16,用不了,还是输出到终端自己拷贝
拷贝输出,效果:
"第⼀讲 证券投资基础" 1 "⼀、了解并掌握证券投资这⻔艺术🐰" 1 "🍼 投资者适应性" 1 "🍼 追涨杀跌为哪般" 1 "🍼 如何培养⾦融嗅觉" 1 "⼆、股票投资ABC🐰" 1 "🍄 中国股市乱象" 1 "🍄 战前总动员" 2 "🍄 中国股票市场的特殊性" 3 "🍄 中国股市的超凡魅⼒" 3 "🍄 选股ABC⸺⾼⼿教你在股市淘⾦" 3 "三、基⾦投资ABC🐰" 3 "🔔 基⾦⾼⼿具备什么特质" 3 "🔔 我国基⺠为何亏钱" 3 "🔔 基⺠和股⺠的投资⽐较和市场认知" 4 "🔔 如何⽤专业的基⾦经理帮你理财" 4 "第⼆讲 证券投资理论" 4 "⼀、资本资产定价模型🍑" 4 "🎯证券投资理论对中国股票市场有什么借鉴意义" 4 "🎯 资本资产定价模型的假设条件" 4 "🎯资本市场线" 5 "🎯资本资产定价模型在实际投资中的应⽤β策略" 6 "🎯资本资产定价模型的局限性" 6 "⼆、有效市场假说🍑" 7 "🎑有效市场假说和有效市场类型" 7 "🎑有效市场中的投资策略分析" 7 "🎑有效市场理论的启示" 8 "三、资产配置策略🍑" 8 "🦐资产配置概述" 8 "🦐常⻅的战略资产配置的执⾏⽅式" 8 "🦐战术资产配置" 9 "🦐动态资产配置" 9 ...导入目录到PDF
1
pdftocio -t toc.txt -o out.pdf 30堂证券投资通识课_无目录版.pdf
问题
编码问题注意一下,都用utf8。在前面注意到了。看到有解决这个问题的PR,但是好像没merge。
标题文字是乱码
另外,在第一个Recipe的查找,发现我的PDF有些字找不到。从PDF复制文字出来,也是现实乱码。相当于这部分字能看到,但是扫描PDF时识别不出来的。这也就导致pdfxmeta扫描元数据时没办法用最后的搜索的文字。
解决方案:
- 找标题中带英文的文字,搜索这个。英文肯定不会乱码。
- 不使用搜索文字功能,去除最后一个参数,直接
pdfxmete -p 1 -a 1 xx.pdf。然后慢慢找标题那段。一般来说标题在最前面,就是最前面那段。
当然了,前面pdfmeta扫不到,后面生成目录也扫不到,也是乱码。这个暂时就只能手输了。
其他工具链
像标准的电子书(即由纸质版而来),一般会有标准的目录,能够直接找到。
相应做法:自动获取书签软件V0505+PdgCntEditor。参考:自动获取书签软件V0505+PdgCntEditor详解_小林9的博客-CSDN博客_书签获取软件